PROBLEM STATEMENT
Netflix provided a lot of anonymous rating data, and a prediction accuracy bar that is 10% better than what Cinematch can do on the same training data set. (Accuracy is a measurement of how closely predicted ratings of movies match subsequent actual ratings.)
ALGORITHMS
XGBoost, Matrix Factorization, Support Vector, KNN Base Line Models.
OBJECTIVES
-
Predict the rating that a user would give to a movie that he ahs not yet rated.
-
Minimize the difference between predicted and actual rating (RMSE and MAPE).
DATA FORMAT
-
Each line in the file corresponds to a rating from a customer and its date in the following format:
CustomerID,Rating,Date
-
MovieIDs range from 1 to 17770 sequentially. CustomerIDs range from 1 to 2649429, with gaps. There are 480189 users. Ratings are on a five star (integral) scale from 1 to 5. Dates have the format YYYY-MM-DD.
TYPE OF MACHINE LEARNING PROBLEM
For a given movie and user we need to predict the rating would be given by him/her to the movie. The given problem is a Recommendation problem It can also be converted as a Regression problem.
PERFORMANCE METRIC
-
Mean Absolute Percentage Error
-
Root Mean Square Error
MACHINE LEARNING OBJECTIVE and CONSTRAINTS
-
Minimize RMSE.
-
Try to provide some interpretability.
EXPLORATORY DATA ANALYSIS
Preprocessing
- Spliting data into Train and Test(80:20)
- Exploratory Data Analysis on Train data
- Distribution of ratings
- Number of Ratings per a month
- Analysis on the Ratings given by user
- Analysis of ratings of a movie given by a user
- number of ratings on each day of the week
- Creating sparse matrix from data frame
- Finding Global average of all movie ratings, Average rating per user, and Average rating per movie
- Computing Similarity matrices
- Computing User-User Similarity matrix
Training the model
- Trying with all dimensions (17k dimensions per user)
- Trying with reduced dimensions (Using TruncatedSVD for dimensionality reduction of user vector)
- Computing Movie-Movie Similarity matrix
- Finding most similar movies using similarity matrix
Machine Learning Steps
- Sampling Data
- Build sample train data from the train data
- Build sample test data from the test data
- Finding Global Average of all movie ratings, Average rating per User, and Average rating per Movie (from sampled train)
- Featurizing data
- Featurizing data for regression problem
Featurizing train and test data
-
GAvg : Average rating of all the ratings
-
Similar users rating of this movie: sur1, sur2, sur3, sur4, sur5 ( top 5 similar users who rated that movie.. )
-
Similar movies rated by this user: smr1, smr2, smr3, smr4, smr5 ( top 5 similar movies rated by this movie.. )
-
UAvg : User’s Average rating
-
MAvg : Average rating of this movie
-
rating : Rating of this movie by this user.
This problem can be solved using following machine learning techniques.
- Recommendation Model
- Regression Model
RECOMMENDATION MODEL
Transforming data for Surprise models:
Transforming train data:
-
We can’t give raw data (movie, user, rating) to train the model in Surprise library.
-
They have a saperate format for TRAIN and TEST data, which will be useful for training the models like SVD, KNNBaseLineOnly….etc..,in Surprise.
-
Form the trainset from a file, or from a Pandas DataFrame.
Transforming test data:
- Testset is just a list of (user, movie, rating) tuples. (Order in the tuple is impotant)
Applying Machine Learning model.
-
Global dictionary that stores rmse and mape for all the models….
It stores the metrics in a dictionary of dictionaries
keys : model names(string) value: dict(key : metric, value : value )
XGBoost with initial 13 features
TEST DATA
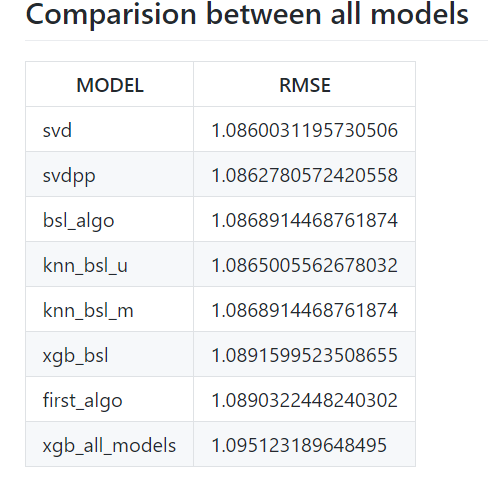
RMSE : 1.0890322448240302
MAPE : 35.13968692492444
Suprise BaselineModel
TEST DATA
RMSE : 1.0865215481719563
MAPE : 34.9957270093008
XGBoost with initial 13 features + Surprise Baseline predictor
TEST DATA
RMSE : 1.0891181427027241
MAPE : 35.13135164276489
Surprise KNNBaseline with user user similarities
Test Data
RMSE : 1.0865005562678032
MAPE : 35.02325234274119
Surprise KNNBaseline with movie movie similarities
Test Data
RMSE : 1.0868914468761874
MAPE : 35.02725521759712
XGBoost with initial 13 features + Surprise Baseline predictor + KNNBaseline predictor
- First we will run XGBoost with predictions from both KNN’s ( that uses User_User and Item_Item similarities along with our previous features.
- Then we will run XGBoost with just predictions form both knn models and preditions from our baseline model.
TEST DATA
RMSE : 1.088749005744821
MAPE : 35.188974153659295
REGRESSION MODEL
Matrix Factorization Techniques
SVD Matrix Factorization User Movie intractions
Test Data
RMSE : 1.0860031195730506
MAPE : 34.94819349312387
SVD Matrix Factorization with implicit feedback from user ( user rated movies )
Test Data
RMSE : 1.0862780572420558
MAPE : 34.909882014758175
XgBoost with 13 features + Surprise Baseline + Surprise KNNbaseline + MF Techniques
TEST DATA
RMSE : 1.0891599523508655
MAPE : 35.12646240961147
XgBoost with Surprise Baseline + Surprise KNNbaseline + MF Techniques
TEST DATA
RMSE : 1.095123189648495
MAPE : 35.54329712868095